2023.04.10 - [IT/Data 분석] - [우주선 생존] 분석 7회차
[우주선 생존] 분석 7회차
2023.04.04 - [IT/Data 분석] - [우주선 생존] 분석 6회차 [우주선 생존] 분석 6회차 2023.04.02 - [IT/Data 분석] - [우주선 생존] 분석 5회차 [우주선 생존] 분석 5회차 2023.03.28 - [IT/Data 분석] - [우주선 생존] 분
songsiaix.tistory.com
독립변수 중 unique 한 값 중 너무 많아서 분포를 확인하기 어려운 애들은 제외하고
VIP, CryoSleep, Destination, HomePlanet 으로만 추려 종속변수와의 분포를 확인해보자.
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import gridspec
features = ['VIP','CryoSleep','Destination','HomePlanet']
grid = gridspec.GridSpec(2,2)
plt.figure(figsize=(8,8))
for idx,feature in enumerate(features):
ax=plt.subplot(grid[idx])
sns.countplot(x=feature,data=df,hue='Transported',palette='pastel',ax=ax)
df[df['VIP']==False]['VIP'].count()
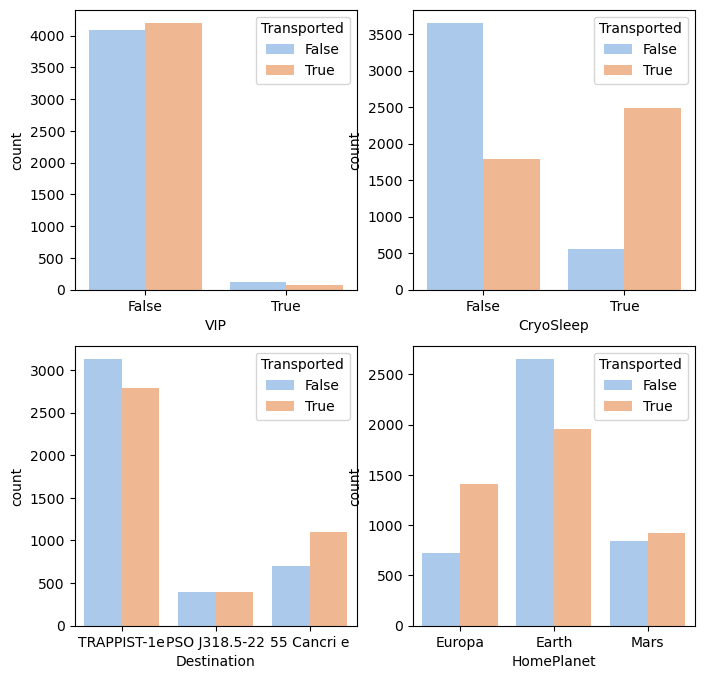
VIP인 분포가 매우 적으며 VIP 가 아닌 사람 중 생존한 사람의 비중은 거의 비슷하다(조금 더 높긴하지만)
목적지 중 'TRAPPIST-1e' 는 분포는 높지만 'Cancri e' 였던 사람들이 생존한 사람의 비중이 다소 높다.(목적지도 의미가 있을 수 있겠다고 생각해본다)
고향행성은 지구에서 출발한 사람들이 높은 분포로 생존하지 못하였다.
냉동수면을 취한 사람의 분포는 36% 정도이긴 하지만 매우 높은 생존률을 보인다.
vc = df.CryoSleep.value_counts()
print(vc)
print(f'False: {round(vc[0]/(vc[0]+vc[1])*100)}% True: {round(vc[1]/(vc[0]+vc[1])*100)}%')
False 5439
True 3037
Name: CryoSleep, dtype: int64
False: 64% True: 36%4개의 독립변수중에 냉동수면 그래프의 경우만 봐도 냉동수면을 한 사람의 생존률이 매우 높다는 것을 알 수 있다.
2023.04.04 - [IT/Data 분석] - [우주선 생존] 분석 6회차
[우주선 생존] 분석 6회차
2023.04.02 - [IT/Data 분석] - [우주선 생존] 분석 5회차 [우주선 생존] 분석 5회차 2023.03.28 - [IT/Data 분석] - [우주선 생존] 분석 4회차 [우주선 생존] 분석 4회차 2023.03.26 - [IT/Data 분석] - [우주선 생존] 분
songsiaix.tistory.com
앞서 6회차에서 봤던 상관관계 그래프를 보면 냉동수면의 상관계수가 0.451744 였다.
절반에는 못 미치지만 거의 절반에 가까운 수치다.
그리고 사실 7, 8회차에서 진행했던 데이터프레임은 Nan을 처리하지 않았다.
그럼에도 불구하고 그래프 처리를 할 때 Nan 가 그래프의 어디에도 존재하지 않았다.
다른 말로 그래프를 처리함에 있어 Nan은 자동으로 무시된다고 이해가 된다.
앞서 사용했던 CryoSleep 처럼 총갯수 - cryosleep의 Nan 갯수의 뺄셈과 Cryosleep의 총 갯수가 동일하다.
print(df.shape[0]-df.CryoSleep.isna().sum(),vc[0]+vc[1])
8476 8476앞선 회차에서 했던 것 처럼 형 변환을 함으로써 자동으로 Nan이 처리될 경우도 한번 해보자.
df = df.astype({'CryoSleep':'bool'})
vc = df.CryoSleep.value_counts()
print(vc)
print(f'False: {round(vc[0]/(vc[0]+vc[1])*100)}% True: {round(vc[1]/(vc[0]+vc[1])*100)}%')
print(df.shape[0]-df.CryoSleep.isna().sum(),vc[0]+vc[1])
False 5439
True 3254
Name: CryoSleep, dtype: int64
False: 63% True: 37%
8693 8693Nan가 자동으로 변환되어 True의 값이 증가하여 36% -> 37% 로 1% 정도 증가 하였다.
비록 1%긴 하지만 Nan이 매우 높았다면 판도를 변화시킬 수 있는 있는 수치도 분명 있을 것 이다.
어쩌면 Nan을 먼저 처리하는 것 보다는 우선 현재 있는 데이터를 그래프로 옮겨보는 것도 초기 분석에는 해볼만한 것 같다.
'IT > Data 분석' 카테고리의 다른 글
| [차원 이동] 분석 10 회차[독립변수 파악] (0) | 2023.04.27 |
|---|---|
| [우주선 생존] 분석 9회차 (0) | 2023.04.15 |
| [우주선 생존] 분석 7회차 (0) | 2023.04.10 |
| [우주선 생존] 분석 6회차 (0) | 2023.04.04 |
| [우주선 생존] 분석 5회차 (0) | 2023.04.02 |